تهران، اقدسیه، خیابان موحد دانش، نبش خیابان نیلوفر، ساختمان پزشکان صاحبقرانیه، طبقه 5، واحد 505
سمعک Real

یکی از جدیدترین مدل های سمعک اتیکن، سمعک Real است که در فوریه 2023 عرضه شد. این سمعک طیف وسیعی از کم شنوایی از ملایم تا شدید را پوشش می دهند و در چهار مدل عرضه می شود، پشت گوشی با باتری یکبار مصرف (miniBTE T)، پشت گوشی با باتری قابل شارژ (miniBTE R)، رسیور داخل کانال با باتری یکبار مصرف (miniRITE T) و رسیور داخل کانال با باتری قابل شارژ (miniRITE R). هر مدل در سه سطح فناوری (1، 2، و 3) موجود است و همه سمعکهای Real دارای رتبه IP68 هستند، به این معنی که در برابر گرد و غبار مقاوم هستند و برای مدت کوتاهی زیر آب تاب می آورند (ضد عرق و باران). بعلاوه این سمعک ها دارای9 رنگ مات متفاوت می باشند.  سمعک Real با گوشی های آیفون و اندروید سازگار است و امکان برقراری تماس تلفنی به صورت هندزفری و استریم کردن از گوشی های هوشمند و دیگر لوازم الکترونیک را به کاربر می دهد. این سمعک ها با به کارگیری پیشرفته ترین تکنولوژی ها برای ارائه دقیق صداهای موجود در محیط، دسترسی بهتر به صحنه صوتی و افزایش آگاهی، تعامل و تمرکز در دنیای واقعی ارائه شده اند. در ادامه به بررسی تکنیکی این سمعک پرداخته می شود.
سمعک Real با گوشی های آیفون و اندروید سازگار است و امکان برقراری تماس تلفنی به صورت هندزفری و استریم کردن از گوشی های هوشمند و دیگر لوازم الکترونیک را به کاربر می دهد. این سمعک ها با به کارگیری پیشرفته ترین تکنولوژی ها برای ارائه دقیق صداهای موجود در محیط، دسترسی بهتر به صحنه صوتی و افزایش آگاهی، تعامل و تمرکز در دنیای واقعی ارائه شده اند. در ادامه به بررسی تکنیکی این سمعک پرداخته می شود.  علیرغم به کار گیری پیشرفته ترین تکنولوژی ها و امکانات در سمعک های Real، تلاش شده که با اعمال تغییراتی جزئی، این نوع سمعک را در 3 رده قیمتی متفاوت متناسب با نیاز طیف وسیعی از کاربران ارائه نمایند. برای مثال سمعک های Real رده 1 بالاترین سطح تکنولوژی و در نتیجه بهترین کیفیت صدا را دارد. از این رو برای افرادی که سبک زندگی پویاتری دارند و پیوسته در محیط های شنیداری متنوع قرار می گیرند کارایی بیشتری خواهد داشت. از سوی دیگر هر چه رده سمعک بالاتر می رود و به رده 3 نزدیکتر می شود، امکانات و تکنولوژی پردازش صدای سمعک ساده تر شده و برای افرادی که در طول روز فعالیت اجتماعی چندانی ندارند و عمده اوقات خود را در منزل سپری می کنند مناسب تر می باشد. در جدول زیر تفاوت های 3 رده مختلف سمعک های Real به صورت خلاصه آمده است:
علیرغم به کار گیری پیشرفته ترین تکنولوژی ها و امکانات در سمعک های Real، تلاش شده که با اعمال تغییراتی جزئی، این نوع سمعک را در 3 رده قیمتی متفاوت متناسب با نیاز طیف وسیعی از کاربران ارائه نمایند. برای مثال سمعک های Real رده 1 بالاترین سطح تکنولوژی و در نتیجه بهترین کیفیت صدا را دارد. از این رو برای افرادی که سبک زندگی پویاتری دارند و پیوسته در محیط های شنیداری متنوع قرار می گیرند کارایی بیشتری خواهد داشت. از سوی دیگر هر چه رده سمعک بالاتر می رود و به رده 3 نزدیکتر می شود، امکانات و تکنولوژی پردازش صدای سمعک ساده تر شده و برای افرادی که در طول روز فعالیت اجتماعی چندانی ندارند و عمده اوقات خود را در منزل سپری می کنند مناسب تر می باشد. در جدول زیر تفاوت های 3 رده مختلف سمعک های Real به صورت خلاصه آمده است:
مقایسه رده های مختلف سمعک Real
| رده 1 | رده 2 | رده 3 | |
| قابلیت ها برای بهبود و تسهیل درک گفتار | |||
| MoreSound Intelligence | سطح 1 | سطح 2 | سطح 3 |
| طبقه بندی محیط | 5 حالت | 5 حالت | 3 حالت |
| تعدیل کننده ویژگی های فضایی | 100 % | 60 % | 60 % |
| Sound Enhancer | 3 حالت | 2 حالت | 1 حالت |
| تثبیت کننده نویز باد و لمس | ✔️ | ✔️ | ✔️ |
| تثبیت کننده اصوات ناگهانی | 6 حالت | 5 حالت | 4 حالت |
| پیشگیری از فیدبک | ✔️ | ✔️ | ✔️ |
| تکنولوژی Spatial Sound | 4 تخمین گر | 2 تخمین گر | 2 تخمین گر |
| تقویت کننده گفتار آهسته | ✔️ | ✔️ | ✔️ |
| انتقال فرکانسی/ Speech Rescue | ✔️ | ✔️ | ✔️ |
| کیفیت صدا | |||
| Clear Dynamics | ✔️ | ✔️ | - |
| تاکید بر گوش برتر | ✔️ | ✔️ | - |
| پهنای باند فرکانسی سمعک | 64 | 48 | 48 |
| کانال پردازشی | 10 کیلوهرتز | 8 کیلوهرتز | 8 کیلوهرتز |
| قابلیت های تنظیم بهینه | |||
| باندهای فرکانسی برای تنظیم | 24 | 20 | 18 |
| گزینه های تعیین دایرکشنالیتی میکروفون | ✔️ | ✔️ | ✔️ |
| برنامه روند عادت پذیری | ✔️ | ✔️ | ✔️ |
| فرمول های تنظیمی | 4 | 4 | 4 |
| قابلیت ارتباط وایرلس | |||
| اپلیکیشن Oticon companion | ✔️ | ✔️ | ✔️ |
| تماس تلفنی به صورت هندزفری | ✔️ | ✔️ | ✔️ |
| استریم مستقیم صدا به سمعک | ✔️ | ✔️ | ✔️ |
| میکروفون ConnectClip | ✔️ | ✔️ | ✔️ |
| EduMic | ✔️ | ✔️ | ✔️ |
| ریموت کنترل | ✔️ | ✔️ | ✔️ |
| رابط TV Adapter | ✔️ | ✔️ | ✔️ |
| سایر | |||
| برنامه Tinnitus SoundSupport | ✔️ | ✔️ | ✔️ |
| سیستم CROS | ✔️ | ✔️ | ✔️ |

پلتفورم Polaris R
این پلتفورم پیشرفته ظرفیت پردازشی بسیار بالایی دارد تا صحنه شنیداری کامل و واضحی را برای کاربران فراهم آورد و در عین حال صداهای مزاحم را با سرعت بالایی حذف نماید. بعلاوه در این پلتفورم یک شبکه عمیق عصبی تعبیه شده که 12 میلیون نمونه صوتی واقعی آموزش دیده است. به این ترتیب می توان اطمینان داشت که اصوات با دقت بسیار بالایی پردازش می شوند و بهینه ترین خروجی در اختیار کاربران سمعک های Real قرار خواهد گرفت. هم چنین دو نوآوری دیگر در این پلتفورم ارائه شده است: sudden sound stabilizer و wind and handling stabilizer که در ادامه به تفصیل شرح داده می شوند. پردازش سیگنال در پلتفورم Polaris R در 24 کانال فرکانسی صورت می گیرد و موجب پردازش دقیق تر صدا و اعمال تقویت جزئی تر و متناسب با نیاز کاربر خواهد شد.

MoreSound Intelligence 2.0
این مدار اصوات را به گونه ای پردازش می کند که بازنمایی طبیعی تر، واضح تر و کاملتری از صحنه شنیداری را ارائه می نماید. بعلاوه تکنولوژی wind & hand stabilizer با حذف کردن نویز اضافی ناشی از باد یا لمس کردن سمعک، ورودی صوتی با کیفیت تری را در اختیار مدار پردازشی MoreSound Intelligence 2.0 خواهد گذاشت که این امر منجر به ارائه خروجی صوتی با کیفیت تر به کاربر می گردد.
پردازش صدا در این مدار در چند بخش صورت می گیرد:
- شناسایی و پیشگیری از ورود نویز باد و لمس کردن: به منظوره ایجاد تجربه شنیداری راحت و دسترسی هر چه بیشتر کاربر به گفتار، به صورت پیوسته سیگنال های ورودی از دو میکروفون موجود بر روی هر سمعک را پایش می کند. سپس ورردی میکروفونی که صاف تر و کم نویز تر باشد را برای پردازش های بعدی وارد مدار پردازشی می نماید.
- اسکن و آنالیز: محیط شنیداری در هر ثانیه 500 مرتبه اسکن می شود که منجر به آنالیز دقیق همه اصوات موجود در محیط خواهد شد.
- پردازش وضوح فضایی: قرار گرفتن سمعک در پشت لاله گوش سبب می شود که اثراتی که ساختار لاله گوش (برجستگی ها و فرورفتگی های آن) بر روی صدای ورودی می گذارد حذف شود. از این رو در این مرحله، تاثیرات لاله گوش بر صدای ورودی شبیه سازی خواهد شد.
- پردازش وضوح عصبی: در مدارهای پردازشی پیشین مبتنی بر الگوریتم هایی بود که مهندسین بر اساس تخمین خود از نحوه پردازش صدا، برای سمعک تعریف کرده بودند. اما پردازش وضوح عصبی متفاوت است. در این روش پردازش صدا به واسطه شبکه عمیق عصبی انجام می گیرد. این شبکه عملکردی مشابه مغز دارد زیرا از طریق تجربه کردن آموزش دیده و بر اساس این دانش، پردازش صدا را انجام میدهد. به همین سبب شبکه عمیق عصبی قادر خواهد بود بین اصوات شناسایی شده کنتراست ایجاد کند و نویزهای ناخواسته را سرکوب نماید.

شبکه عمیق عصبی
شبکه عمیق عصبی یک قابلیت هوشمند است که همانند مغز نیاز دارند آموزش ببیند و یاد بگیرد. وقتی DNN آموزش دید و یاد گرفت که چگونه صحنه های صوتی را پردازش کند، می تواند از این دانش برای پردازش هر صحنه صوتی ارائه شده به آن استفاده نماید. این ویژگی هوشمند است عملکرد به مراتب بهتری از الگوریتم های ساخته شده توسط انسان دارد. برای آموزش DNN، از 12 میلیون صحنه های صوتی واقعی استفاده می شود که با استفاده از یک میکروفون کروی ضبط شده اند. این میکروفون کروی دارای 32 میکروفن پیشرفته و منفرد است که به طور مساوی در سراسر کره توزیع شده و امکان ضبط صحنه های صوتی با جزئیات مکانی و دقت را فراهم می کند. بسیار حائز اهمیت است که یک DNN به اندازه کافی برای وظیفه محوله آموزش دیده باشد. به عبارت بهتر اگر میزان آموزش کم باشد، دانش کافی برای مدیریت تمام صحنه های صوتی را نخواهد داشت و در نتیجه خطاهای زیادی مرتکب می شود و اگر بیش از حد تمرین شده باشد، برای رسیدگی به صحنه های صوتی واقعی متفاوت از آنچه در آموزش استفاده شده است، بسیار تخصصی خواهد بود.

MoreSound Amlifier 2.0
در سمعک های Real از یک سیستم تقویت کننده جدید با عنوان MoreSound Amlifier 2.0. استفاده شده است دارای چند ویژگی می باشد. یکی از ویژگی های جدید این سیستم، SuddenSound Stabilizer است که با سرعت و دقت بسیار بالایی صداهای ناگهانی بلند یا آهسته را مدیریت می کند و با حفظ کنتراست بین اصوات مختلف مانع از ایجاد احساس آزردگی برای کاربر می شود. در این سیستم اصوات ورودی در 24 کانال مورد پردازش قرار می گیرند و بر اساس نوع ورودی هر کانال خود سمعک تصمیم می گیرد که کدام کانال ها باید در الویت قرار بگیرند و به چه میران تقویت شوند و برای کدام کانال ها تقویت کمتری اعمال گردد. به این ترتیب اطلاعات بهتر و دارای وضوح فرکانسی بیشتر در اختیار مغز کاربر قرار خواهد گرفت.
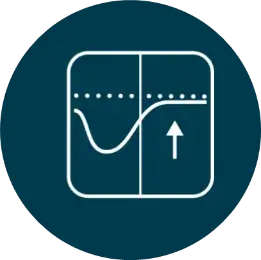
MoreSound Optimizer
این یک تکنولوژی پیشرفته است که امکان دسترسی به جزئیات گفتار را به شکلی کاملا طبیعی را فراهم آورده و درک گفتار را حتی در محیط های دشوار افزایش می دهد. بعلاوه این سیستم احتمال وقوع فیدبک را به سرعت شناسایی کرده و پیش از وقوع، از شکل گیری آن پیشگیری می کند و مانع از فعال شدن سیستم مدیریت فیدبک و ایجاد تغییر در سیستم تقویت کننده می شود.

Spatial Sound
ترکیبی از چند تکنولوژی پیشرفته است که موجب افزایش دقت آگاهی فضایی کاربر شده و به او کمک می کند تا بهتر بتواند تشخیص دهد که صدا از کجا می آید.

Speech Rescue
کم شنوایی در فرکانس های بالا سبب غیرقابل شنیدن شدن اصوات گفتاری مانند /س/ و /ش/ می شود که تاثیر سوئی بر درک گفتار می گذارد. رویکرد اتیکن برای غلبه بر این مشکل، تکنولوژی انتقال فرکانسی است با عنوان Speech Rescue. یکی از مطلوب ترین تکنولوژی ها در افراد مبتلا به کم شنوایی متوسط تا شدید-عمیق است. در این افراد افت شنوایی در فرکانس های بالا به حدی زیاد است که صرفا تقویت سیگنال گفتاری کمکی به آنها نخواهد کرد. این تکنولوژی به بازیابی و حفظ محتویات فرکانس بالای سیگنال های گفتاری کمک میکند. به این شکل که قسمت فرکانس بالای سیگنال گفتاری را به مناطق فرکانسی پایین تر که از شنوایی بهتری برخوردارند انتقال داده تا برای کاربر قابل شنیدن باشند.

محافظ فیدبک/ Feedback Sheild
محافظ فیدبک در کنار MoreSound Optimizer باعث ایجاد یک واکنش فوق سریع به احتمال وقوع فیدبک شده و به طور کلی مانع از شکل گیری فیدبک می شوند. سیستم محافظ فیدبک از دو مسیر مجزا برای هر میکروفون عمل می کند. در هر مسیر 3 تکنیک با یکدیگر برای سرکوب کردن فیدبک و ثابت نگه داشتن میزان تقویت لازم فعالیت می نمایند که عبارتند از تغییر فرکانس، معکوس کردن فاز و کاهش میزان تقویت. فعالیت توامان این دو تکنولوژی در کنار، مانع از استفاده زیاد از تکنیک کاهش میزان تقویت در فرکانس فیدبک می شود و تغییری در کیفیت صدا ایجاد نخواهد شد.
 Tinnitus SoundSupport
Tinnitus SoundSupport
این تکنولوژی طیف وسیعی از صداها را متناسب با نیاز و سلیقه کاربران، برای فرآیند صدا درمانی وزوز ارائه می دهد. این صداها عبارتند از صداهای با پهنای باند فرکانسی گسترده مانند نویزهای ساخته شده بر اساس ادیوگرام، نویز سفید، نویز صورتی و نویز قرمز و سه صدای اقیانوس. کاربر می تواند با استفاده از اپلیکیشن companion تنطیمات صداهای پوشاننده وزوز را متناسب با نیاز خود تغییر دهد.

TWINLINK
این تکنولوژی با استفاده از بلوتوث Low Energy بین سمعک های دو گوش و نیز دیگر لوازم الکترونیک و اکسسوری ها ارتباط برقرا می کند. در افراد مبتلا به ناشنوایی یکطرفه می توان با قرار دادن یک سمعک دارای تکنولوژی TwinLink بر روی گوش ضعیف تر، صداها را دریافت نموده و از طریق القای مغناطیسی اطلاعات را به سمعک روی گوش بهتر انتقال داد. به این ترتیب فرد قادر خواهد بود که در محیط های مختلف، مکالمات فرد دیگری که در سمت گوش ضعیف تر او قرار دارد را نیز بشنود.
شارژر باتری
اتیکن برای سمعک های پشت گوشی و رسیور داخل کانال شارژی Real دو نوع شارژر ارائه کرده است: شارژر رومیزی و شارژر پرتابل/قابل حمل Smart. هر دو شارژر دارای تکنولوژی القایی هشیتند تا بتوانند امکام شارژ سریع و مطمئن را فراهم آورند
- شارژر smart را هم می توان به برق متصل کرد و هم می توان به عنوان پاور بانک در خارج از منزل استفاده نمود. در صورت شارژ کامل شارژر، می توان از ذخیره آن برای سه مرتبه شارژ کردن کامل سمعک ها استفاده نمود. طول عمر بالای باتری و امکان شارژ چندباره برای کاربران اطمینان خاطر ایجاد خواهد کرد، حتی وقتی خاج از منزلند و دسترسی به برق شهری ندارند. این شارژر دارای یک درب است که هنگام شارژ کردن، جابجایی یا نگهداری سمعک از آنها مراقبت می کند. از دیگر ویژگی های خوب شارژر Smart، سیستم خشک کن آن است. به این معنا که رطوبت موجود در سمعک در حین شارژ شدن خشک خواهد شد و نیازی به خشک کن مجزا نمی باشد.
- شارژر رومیزی برای استفاده در منزل یا محیط کار تعبیه شده است. و نیاز به اتصال دائم با برق شهری دارد.
قابلیت های اتصال و اکسسوری ها
- استریم کردن تماس های تلفنی یا صدای موسیقی از گوشی های موبایل به سمعک به صورت وایرلس
- اپلیکیشن Oticon Companion: این اپ را به راحتی میتوان از اپ استور یا گوگل پلی دانلود کرد و از آن به عنوان ابزاری برای کنترل تنظیمات سمعک استفاده نمود. از طریق این اپلیکیشن، فرد می تواند
- ✔️ صدای سمعک خود را کم و زیاد کند یا برنامه سمعک را تغییر دهد.
- ✔️ سطح باتری سمعک را پایش کند.
- ✔️ از حالت تقویت کننده گفتار/ Speech Booster برای کاهش نویز محیط و افزایش صدای گفتاری و تمرکز بیشتر بر مکالمات استفاده نماید.
- ✔️ در هنگام گوش دادن به موسیقی یا استریم کردن سایر اصوات، تنظیمات دقیق تری بر روی صدا اعمال نماید.
- ✔️ با دیگر اکسسوری های متصل به سمعک، مانند TV Adapter یا ConnectClip ارتباط وایرلس برقرار کند
- ✔️ با ادیولوژیست خود ارتباط مجازی برقرار کرده و در برخی از تنظیمات سمعک تغییراتی اعمال نماید.

- TV Adapter: این اکسسوری امکان استریم مستقیم و وایرلس صدای تلویزیون به سمعک Real را میسر می سازد و کاربر می تواند بدون ایجاد تغییر در صدای تلویزیون، صدای آن را در سمعک خود کم یا زیاد کند.
- سیستم لوپ: سمعک های Real مجهز به مدار تله کویل هستند و در صورت قرار گرفتن در محیط های دارای سیستم لوپ می توانند از طریق القای الکترومغناطیسی صداها را دریافت نمایند.
- شنیدن از فواصل دور با استفاده از ConnectClip یا EduMic: این دو وسیله در حقیقت نوعی ریموت میکروفون هستند که امکان استریم کردن صدای فرد گوینده به سمعک را به طور مستقیم فراهم می کنند. به این ترتیب حتی در محیط های شلوغ یا از فاصله دور هم کاربر به راحتی صدای فرد مقابل را بدون هیچ خدشه و نویزی خواهد شنید.
- کنترل سمعک با ریموت کنترل: وسیله ای کوچک است که از طریق آن می توان به سادگی و پنهانی تغییراتی بر صدا و برنامه ای سمعک اعمال نمود بدون اینکه لازم باشد سمعک را از گوش درآورده یا به آن دست بزنید. بعلاوه ریموت کنترل برا آن دسته از کاربرانی که مشکل لرزش دست دارند . به راحتی نمی توانند دکمه های کوچک سمعک را لمس کنند کارآیی قابل توجهی دارد.